http://www.itworld.co.kr/news/110672?page=0,0#csidx4bca9e1ee1e67bcbd7b712f82aca7fc 
GPU 병렬 프로그래밍 CUDA의 모든 것
CUDA와 GPU의 병렬 처리 능력을 활용하면 딥러닝을 포함한 컴퓨팅 집약적 애플리케이션을 가속화할 수 있다.
CUDA 는 엔비디아가 자체 GPU에서의 일반 컴퓨팅을 위해 개발한 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델이다, CUDA는 개발자가 연산의 병렬화할 수 있는 부분에 GPU의 성능을 활용해 컴퓨팅 집약적인 애플리케이션의 속도를 높일 수 있도록 해준다.
OpenCL과 같이 GPU용 API도 있고, AMD 같은 다른 업체의 경쟁력 있는 GPU도 있지만, CUDA와 엔비디아 GPU의 조합은 딥러닝을 포함한 여러 애플리케이션 영역을 장악하고 있다. 이 조합은 또한 세계에서 가장 빠른 몇몇 슈퍼컴퓨터의 기반이기도 하다.

그래픽 카드는 PC만큼이나 오래 되었다고 할 수 있다. 물론, 어디까지나 1981년 IBM 모노크롬 디스플레이 어댑터를 그래픽 카드라고 간주하는 경우에 그렇다. 1988년이 되자 ATI(나중에 AMD에 인수)에가 16비트 2D VGA 원더 카드를 내놓았다. 1996년에는 3dfx 인터랙티브가 3D 그래픽 가속기를 출시해 1인칭 슈팅 게임인 퀘이크(Quake)를 최고 속도로 실행할 수 있게 되었다.
엔비디아는 1996년 다소 빈약한 제품으로 3D 액셀러레이터 시장 경쟁에 뛰어들었지만, 시간이 지나면서 그것만으로는 부족함을 알게 되었다. 1999년에 엔비디아는 처음으로 GPU라고 불린 최초의 그래픽 카드 ‘지포스 256’을 선보였다. 당시만 해도 GPU는 주로 게임을 위해서만 사용했다. 사람들이 수학, 과학, 공학에 GPU를 사용한 것은 더 시간이 지나고 나서였다.
CUDA의 기원
2003년에 이안 벅이 이끄는 연구팀은 데이터 병렬 구조로 C를 확장해 최초로 널리 채택된 프로그래밍 모델인 브룩(Brook)을 공개했다. 벅은 이후 엔비디아에 합류해 2006년에 GPU 상의 범용 컴퓨팅을 위한 최초의 상용 솔루션인 CUDA의 출시를 주도한다.
OpenCL vs. CUDA
CUDA의 경쟁자인 OpenCL은 2009년 애플과 크로노스 그룹(Kronos Group)이 인텔/AMD CPU에만 국한되지 않는 이기종 컴퓨팅 표준을 제공하기 위해 출시했다. OpenCL은 그 일반성 때문에 매력적으로 들리지만, 엔비디아 GPU와 CUDA 조합만큼의 성능을 보여주지 못했으며, 많은 딥러닝 프레임워크가 OpenCL을 지원하지 않거나, CUDA를 먼저 지원하고 OpenCL 지원은 추후에 이루어지는 경우가 많다.
CUDA 성능 가속화
CUDA는 몇 년 동안 엔비디아 GPU의 개선과 더불어 활용 범위를 넓혀 왔다. 여러 개의 P100 서버 GPU를 사용하는 CUDA 버전 9.2는 CPU에 비해 최대 50배 향상된 성능을 실현할 수 있다. 로드에 따라서는 V100(이 그림에는 표시되지 않음)이 여기서 추가적으로 3배 더 빠른 성능을 보여준다. 이전 세대의 서버 GPU인 K80은 CPU에 비해 5배~12배 향상된 성능을 보여주었다.
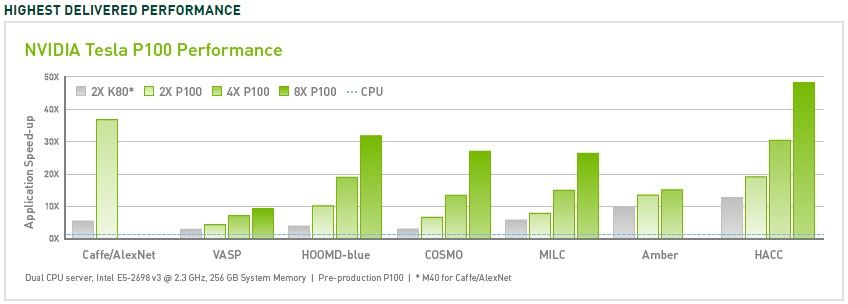
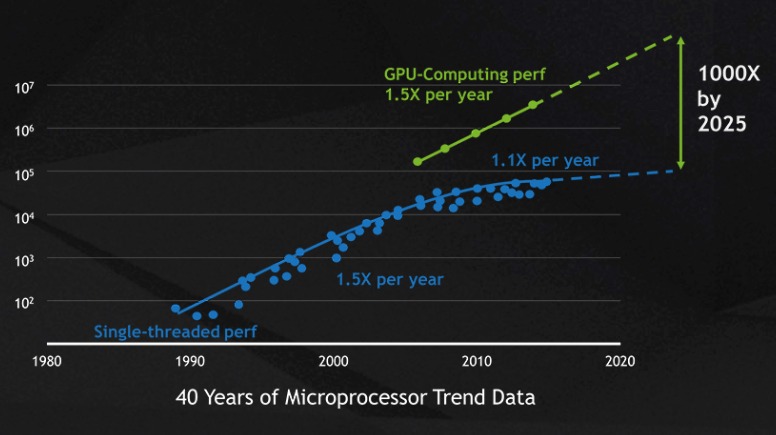
GPU의 속도 향상은 고성능 컴퓨팅에 맞추어 적시에 이루어졌다. 무어의 법칙에 따르면 매 18개월마다 2배로 증가하게 되어 있다고 하는 CPU의 단일 쓰레드 성능 향상은 칩 제조업체들이 칩 마스크 해상도의 크기 제한과 칩 생산량, 그리고 런타임에서의 클럭속도와 열 제한 같은 물리적 한계에 부딪히면서 매년 10%까지 감소해 왔다.
CUDA 적용 영역

그림에서 보듯이 CUDA와 엔비디아 GPU는 높은 부동 소수점 컴퓨팅 성능을 필요로 하는 여러 분야에서 도입했다. 좀더 보다 포괄적인 목록은 다음과 같다.
1. 컴퓨터 재정학(Computational finance)
2. 기후, 날씨 및 해양 모델링
3. 데이터 과학 및 분석
4. 딥러닝 및 머신러닝
5. 국방 및 첩보 활동
6. 제조/AEC(Architecture, Engineering, and Construction): CAD 및 CAE (전산유체역학, 전선구조역학, 설계 및 시각화, 전자설계 자동화 등 포함)
7. 미디어 및 엔터테인먼트(애니메이션, 모델링 및 렌더링, 색 보정 및 그레인 관리, 영상 합성, 편집, 인코딩 및 디지털 배포, 온에어 그래픽, 온세트, 리뷰 및 스테레오 툴, 날씨 그래픽 등).
8. 의료 영상
9. 석유 및 가스
10. 연구: 고등교육 및 슈퍼컴퓨터 (컴퓨터 화학, 생물학, 수치 해석학, 물리학, 과학적 시각화 등)
11. 안전 및 보안
12. 도구 및 관리
딥러닝과 CUDA
딥러닝은 엄청난 연산 속도를 필요로 한다. 예를 들어, 2016년 구글 브레인 및 구글 트랜슬레이트 팀은 구글 번역 모델을 교육하기 위해 GPU를 사용하여 1주일 단위로 수백 차례 텐서플로우를 실행했다. 두 팀은 이를 위하여 엔비디아로부터 2,000대의 서버급 GPU를 구입하기도 했다. GPU가 없었다면, 이런 학습은 1주일이 아니라 몇 달이 걸릴 것이다. 텐서플로우 변환 모델의 생산을 위해 구글은 새로운 맞춤형 칩인 TPU(Tensor Processing Unit)를 사용했다.
원문보기:
http://www.itworld.co.kr/news/110672?page=0,0#csidx4bca9e1ee1e67bcbd7b712f82aca7fc
텐서플로우 외에도, 많은 다른 딥러닝 프레임워크가 Caff2, CNTK, Databricks, H2O.ai, Keras, Torcho, Torch를 포함한 GPU 지원을 위해 CUDA를 사용한다. 대부분의 경우 심층 신경망 컴퓨팅을 위해 cuDNN 라이브러리를 사용한다. 이 라이브러리는 딥러닝 프레임워크의 훈련에 매우 중요하기 때문에 특정 버전의 cuDNN을 사용하는 모든 프레임워크는 동등한 사용례에 대해 기본적으로 동일한 성능 수치를 갖는다. CUDA와 cuDNN이 버전마다 개선되면서 새로운 버전으로 업데이트하는 모든 딥러닝 프레임워크가 동일한 성능 상의 이득을 누리게 된다. 성능이 프레임워크마다 다른 이유는 여러 GPU 및 여러 노드로 얼마나 잘 확장하느냐에 있다.
CUDA 프로그래밍
CUDA 툴킷
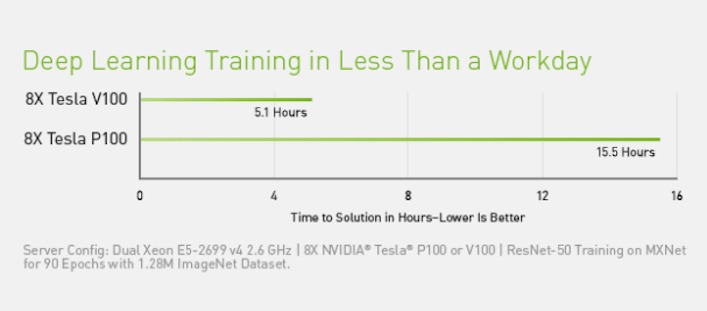
CUDA 툴킷에는 라이브러리, 디버깅 및 최적화 도구, 컴파일러, 문서화 및 애플리케이션 배포를 위한 런타임 라이브러리가 포함된다. CUDA 툴킷은 딥러닝, 선형 대수, 신호 처리 및 병렬 알고리즘을 지원하는 요소들을 가지고 있다. 일반적으로 CUDA 라이브러리는 엔비디아 GPU의 모든 제품군을 지원하지만, 딥러닝 교육 워크로드의 경우 P100보다 3배 가량 빠른 V100과 같은 최신 모델에 가장 적합하다. 필요한 알고리즘이 적절한 라이브러리에 구현되어 있다면, 하나 이상의 라이브러리를 사용하는 것이 GPU를 가장 쉽게 활용할 수 있는 방법이다.
CUDA 딥러닝 라이브러리
딥러닝 영역에는 세 가지 주요 GPU 가속화 라이브러리가 존재한다. cuDNN은 앞서 말했듯 대부분의 오픈소스 딥러닝 프레임워크의 GPU 구성요소이며, TensorRT는 엔비디아의 고성능 딥러닝 추론 최적화기이자 런타임이라 할 수 있다. 또, 비디오 추론 라이브러리인 딥스트림(DeepStream)도 있다. TensorRT는 신경망 모델을 최적화하고, 낮은 정확도를 보정하며, 훈련된 모델을 클라우드, 데이터센터, 내장 시스템 또는 자동차 제품 플랫폼에 배포하기도 한다.
CUDA 선형 대수 및 수학 라이브러리
선형 대수는 텐서 연산과 딥러닝의 기반이 된다. 그 동안 과학자들과 엔지니어들은 1989년 포트란에서 구현된 매트릭스 알고리즘의 집합체인 BLAS(Basic Linear Algear Subprograms)를 사용해 왔다. cuBLAS는 BLAS의 GPU 가속화 버전이며, GPU를 사용해 가장 높은 성능의 연산을 수행하는 방법이다. cuBLAS는 매트릭스가 조밀하다고 가정한다. cuSPARSE가 매트릭스를 처리한다.
CUDA 신호 처리 라이브러리
FFT(Fast Fourier Transform)는 신호 처리에 사용되는 기본 알고리즘 중 하나이며, 신호(예를 들어 오디오 파형)를 주파수의 스펙트럼으로 변환하는 기능을 한다. cuFFT는 GPU 가속화된 FFT라 할 수 있다. H.264와 같은 표준을 사용하는 코덱은 전송 및 디스플레이를 위해 비디오를 인코딩/압축 및 디코딩/디컴프레스 한다. 엔비디아 비디오 코덱 SDK는 GPU를 통해 이 프로세스의 속도를 높여준다.
CUDA 병렬 알고리즘 라이브러리
병렬 알고리즘을 위한 세 라이브러리는 모두 다른 목적을 가지고 있다. NCCL (Nvidia Collective Communications Library)은 여러 GPU 및 노드에 걸쳐 앱을 확장하기 위한 것이며, nvGRAPH 는 병렬 그래프 분석을 위한 것이다. Thrust는 CUDA를 기반으로 하는 C++ 스탠다드 템플릿 라이브러리이다. Thrust는 스캔, 정렬 및 감소와 같은 다양한 데이터 병렬 원형을 제공한다.
CUDA vs. CPU 성능
경우에 따라 CPU 기능 대신 드롭인 형식의 CUDA 기능을 사용할 수도 있다. 예를 들어 BLAS의 GEMM 행렬 곱셈(matrix multiplication) 루틴은 NVBLAS 라이브러리에 연결하기만 하면 GPU 버전으로 대체할 수 있다.

CUDA 프로그래밍 기본
알맞은 CUDA 라이브러리 루틴을 찾을 수 없는 경우 저수준 CUDA 프로그래밍을 시도해 볼 수밖에 없다. 그래도 요즘은 2000년대 말보다는 훨씬 쉽게 할 수 있을 것이다. 여러 가지 이유가 있겠지만, 무엇보다 신택스(syntax)가 쉬워지고, 개발 툴도 더 나아졌기 때문이다. 필자의 유일한 불만이라면, 맥OS에서는 최신 CUDA 컴파일러와 최신 C++ 컴파일러(Xcode)가 동기화되는 경우가 거의 없다는 것이다. 때문에 애플에서 옛날 명령어줄 툴을 다운로드하고 xcode-select를 사용하여 해당 도구로 전환하여 CUDA 코드를 컴파일하고 연결해야 한다.
예를 들어, 다음 2개의 어레이를 추가하는 간단한 C/C++ 루틴을 보자.
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
선언에 __global__ 키워드를 추가해 GPU에서 실행될 커널로 전환하고, 삼중 괄호 구문을 사용하여 커널을 호출할 수 있다.
add<<<1, 1>>>(N, x, y);
또한 malloc/new와 free/delete 콜을 cudaMallocManaged와 cudaFree로 바꿔야만 GPU에서 공간을 할당할 수 있다. 마지막으로, CPU 결과를 사용하기 전에 GPU 계산이 완료될 때까지 기다려야 한다. 이것은 cudaDeviceSynchronize를 통해 구현할 수 있다.
삼중 괄호는 하나의 쓰레드 블록과 하나의 쓰레드를 사용한다. 현재 엔비디아 GPU는 많은 블록과 쓰레드를 처리할 수 있다. 예를 들어, 파스칼 GPU 아키텍처를 기반으로 하는 테슬라 P100 GPU는 각각 최대 2,048개의 액티브 쓰레드를 지원할 수 있는 56개의 스트리밍 프로세서를 보유하고 있다.
커널 코드가 전달된 어레이로 오프셋을 찾으려면, 해당 블록 및 쓰레드 인덱스를 알아야 한다. 병렬화된 커널은 다음과 같은 그리드 스트라이드(grid-stride) 루프를 사용하는 경우가 많다.
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
CUDA 툴킷의 샘플을 보면 앞에서 다룬 기본 사항보다 더 많은 사항을 고려해야 한다는 것을 알 수 있다. 예를 들어 CUDA 함수 호출 중 일부는 checkCudaErrors() 호출을 통해 처리되어야 한다. 또한 대부분의 경우 가장 속도가 빠른 코드는 호스트 및 장치 메모리의 할당, 매트릭스의 복사와 함께 cuBLAS와 같은 라이브러리를 사용하게 된다.
요약하자면, 다양한 수준에서 GPU를 사용하여 애플리케이션을 가속화하는 것이 가능하다. CUDA 코드를 작성하고 CUDA 라이브러리를 호출할 수 있으며, 이미 CUDA를 지원하는 애플리케이션을 사용할 수도 있다. editor@itworld.co.kr
원문보기:
http://www.itworld.co.kr/news/110672?page=0,1#csidxc8f65be6352dcdeabe02ffa90995f10 
'IT 학습 Learning' 카테고리의 다른 글
| Data Science and Python Pandas (0) | 2018.11.06 |
|---|---|
| Javascript for Numerical Library (0) | 2018.10.24 |
| Parallel Processing & Cuda (0) | 2018.10.13 |
| edX Courses - Oct. 10, 2018 (0) | 2018.10.10 |
| edX Courses - Sep. 2018 (1) | 2018.09.16 |




















